
MiniMax M3 vs DeepSeek V4 Pro: Which Model Is Better for AI Agents?
Автор: Alex Morgan
Редакция AgentCellar
AgentCellar
Запустите OpenClaw прямо сейчас
Посмотрите, как хостинг, автоматизация, платежи, поддержка и операции OpenClaw объединяются в единый управляемый продукт.
AI Takeaway
- Which model is better for coding agents? MiniMax M3 is the better test when the task needs long context, screenshots, browser state, or longer agent sessions. DeepSeek V4 Pro is the better first test when cost, reasoning, and text-heavy coding throughput matter most.
- Which model is cheaper to run? DeepSeek V4 Pro has the clearer low-cost story today, especially for high-volume API work. Total cost still depends on retries, output length, and the runtime around the model.
- Does 1M context decide the winner? No. Long context helps only when the agent can find and use the right files, logs, tool results, and visual context.
- What should you compare? Completion rate, retry count, tool-call accuracy, cost per completed task, and how well the model recovers after failure.
MiniMax M3 vs. DeepSeek V4 Pro at a Glance
MiniMax M3 and DeepSeek V4 Pro both point toward cheaper long-context models that can power real AI agents, not just chat answers.
MiniMax M3 is more compelling when an agent needs screenshots, browser state, UI inspection, diagrams, long repo context, and multi-step tool use. DeepSeek V4 Pro is more compelling when the workload is mostly text, code, logs, structured output, and repeated reasoning.
| Area | MiniMax M3 | DeepSeek V4 Pro |
|---|---|---|
| Best fit | Multimodal, long-context, tool-heavy agents | Low-cost coding, reasoning, and text-heavy agents |
| Strongest case | Visual and desktop-like workflows | Cost-sensitive high-volume workflows |
| First test | Large repo, screenshot, browser, UI task | Code review, log analysis, summaries, reasoning |
For more context on the model itself, the MiniMax M3 guide covers its agent angle, MiniMax M3 API considerations, and MiniMax M3 1M context tradeoffs.
The Real Difference Is Agent Work, Not Chat Quality
Chat Answers Are Too Easy to Compare
A normal chat test can make two models look closer than they really are. Ask each one to summarize a topic, write a function, or explain an error, and both may look strong. An agent has to do messier work: read files, choose tools, check output, change direction, and keep going after something breaks.
That is where MiniMax M3 and DeepSeek V4 Pro start to separate. The best model for AI agents is not always the strongest model on a single answer; it is the model that keeps the workflow moving. MiniMax M3 deserves attention for work with visual or broad-context input. DeepSeek V4 Pro deserves attention when you need many reliable text and coding runs without letting API cost quietly grow.
Cost per Completed Task Beats Token Price
Token pricing matters, but it is not the final answer. A model can look low-cost per million tokens and still become expensive if it needs three attempts to finish one job. Another model can cost more per token but save money by completing the task cleanly.
For agent work, track the whole run: planning, file reads, tool output, retries, final response, human corrections, and overall AI agent model cost. This is especially important for software work. A model that writes plausible code but misses test failures is not actually low-cost. It just moves the cost into debugging. A dedicated coding agent workflow is a better test than a single playground prompt, especially if you are choosing the best model for coding agents, and a stronger signal than any isolated MiniMax M3 benchmark.
Where MiniMax M3 Looks Stronger
Long-Context Agent Work
 MiniMax M3 is most interesting when context is the bottleneck. Large repos, long support histories, browser research, policy documents, transcripts, test logs, and multi-step sessions all benefit from a model that can hold more of the task at once.
MiniMax M3 is most interesting when context is the bottleneck. Large repos, long support histories, browser research, policy documents, transcripts, test logs, and multi-step sessions all benefit from a model that can hold more of the task at once.
That does not mean you should dump everything into context and hope for magic. Long context still needs selection. The model has to find the few important facts inside a large pile of files and logs. But if your current model keeps losing track of prior steps, MiniMax M3 is worth testing.
Multimodal and Desktop-Like Workflows
The bigger difference is multimodal work. If your agent needs to inspect screenshots, charts, browser states, UI errors, product pages, or dashboard output, MiniMax M3 has the more natural story.
Many real workflows are not purely text. A coding task may include a failed Playwright screenshot; a support task may include a broken dashboard. A model that can understand those inputs directly can reduce the handoff between “look at this” and “act on it.”
Coding With Tools, Not Just Code Generation
The right coding test is not “which model writes the prettier function?” In MiniMax M3 vs DeepSeek for coding, the better question is whether the model can inspect a repo, edit the right files, run commands, read failures, and recover. MiniMax M3 may be strongest when the coding task is tied to logs, UI state, browser output, screenshots, and long repo context.
If you are already comparing MiniMax versions, the MiniMax M2 vs M3 article is a useful companion because M2-style stability may still matter for production workflows.
Where DeepSeek V4 Pro Looks Stronger
Cost-Sensitive Reasoning and Coding
 DeepSeek V4 Pro is the first model to test when the work is text-heavy and frequent. That includes code review, bug triage, log analysis, summarization, document processing, structured extraction, internal assistants, and repeated automation.
DeepSeek V4 Pro is the first model to test when the work is text-heavy and frequent. That includes code review, bug triage, log analysis, summarization, document processing, structured extraction, internal assistants, and repeated automation.
Lower cost changes how often you can use a model. A model affordable enough to run on every support ticket, pull request, or research batch can become more useful than a stronger model reserved for special cases.
1M Context Without Premium Expectations
 A 1M context window is useful when the task needs lots of relevant material nearby. The DeepSeek V4 Pro 1M context story matters because it brings that capability into a lower-cost lane. That is why DeepSeek V4 Pro pricing and DeepSeek V4 Pro API limits should be checked before planning high-volume work.
A 1M context window is useful when the task needs lots of relevant material nearby. The DeepSeek V4 Pro 1M context story matters because it brings that capability into a lower-cost lane. That is why DeepSeek V4 Pro pricing and DeepSeek V4 Pro API limits should be checked before planning high-volume work.
Still, long context is not a reason to pass everything. If a task needs ten files, pass ten files. The goal is not to maximize context. The goal is to help the model finish.
Text-First Agent Tasks
If the agent mostly reads and writes text, DeepSeek V4 Pro may be the more practical default. It is less dependent on the multimodal promise and easier to evaluate with repeated tests: same repo, same log, same document set, same extraction task.
A useful rule: if the task can be completed without screenshots or visual state, start with DeepSeek V4 Pro. If the task depends on what the agent sees on screen, add MiniMax M3 to the test set.
{{myclaw_blog_cta}}
The Decision Framework: Pick by Workload
Choose MiniMax M3 If the Agent Needs to See More
Use MiniMax M3 when the work involves screenshots, browser sessions, visual QA, UI inspection, large repos, long research sessions, or mixed text-image inputs. It is also a good candidate when your current model keeps losing track of a long task.
Choose DeepSeek V4 Pro If Cost Controls the Workflow
Use DeepSeek V4 Pro when you need frequent runs: daily code reviews, support summaries, log diagnosis, document processing, internal search, or batch reasoning. If the model is reliable enough, lower cost can make the entire workflow easier to scale.
Use Both for a Serious Agent Stack
A serious agent stack should not depend on one model for everything. In MiniMax M3 vs DeepSeek for agents, the practical answer is often routing: use a lower-cost model for routine work, a multimodal model for visual or long-horizon tasks, and a fallback when a provider is slow or unavailable.
This is also a practical way to think about OpenClaw model comparison. If you are deciding more broadly, the best model for OpenClaw guide covers cloud, local, and fallback options.
How to Test MiniMax M3 vs DeepSeek V4 Pro
Test Completed Tasks, Not Demo Prompts
Build a small test set from real work. Try a multi-file bug, a long test log, a large document set, a source comparison, a screenshot failure, and one repeated workflow. The repeated run matters: a model that succeeds once and fails four times is not ready for automation.
Track the Metrics That Matter
| Metric | Why It Matters |
|---|---|
| Completion rate | Did the task actually finish? |
| Retries | Did the model recover or loop? |
| Time to finish | Was the run practical? |
| Tool accuracy | Did it call the right tools with the right inputs? |
| Total cost | What did one finished task cost? |
| Human intervention | How often did you need to rescue it? |
Run the Test in the Same Environment
Do not compare MiniMax M3 in one tool and DeepSeek V4 Pro in another. Keep the runtime fixed and only change the model: same files, same tools, same budget, same permissions.
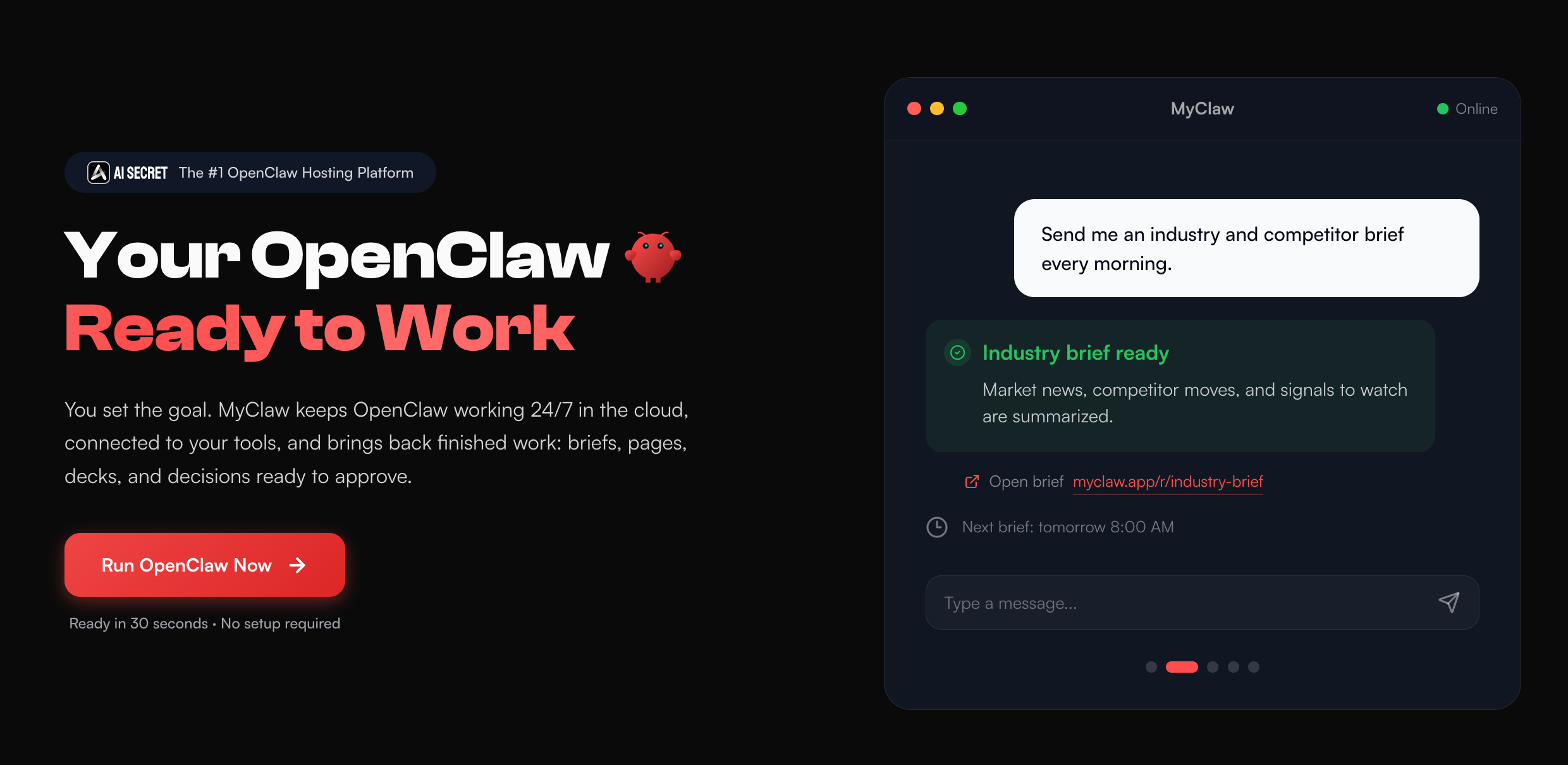 OpenClaw is a good place to run this comparison because the model has to perform real actions instead of only answering. If you want an OpenClaw DeepSeek setup and an OpenClaw MiniMax setup without turning the experiment into server work, MyClaw gives you a hosted OpenClaw environment where you can focus on model behavior rather than VM maintenance, uptime, and manual configuration.
OpenClaw is a good place to run this comparison because the model has to perform real actions instead of only answering. If you want an OpenClaw DeepSeek setup and an OpenClaw MiniMax setup without turning the experiment into server work, MyClaw gives you a hosted OpenClaw environment where you can focus on model behavior rather than VM maintenance, uptime, and manual configuration.
The best OpenClaw hosting guide covers that setup side in more detail.
Keeping Agent Cost and Reliability Under Control
Set Budgets Before Scaling
Long-context agents can burn tokens quietly. Set task-level budgets, retry limits, and monthly usage caps before you turn a workflow into daily automation. A simple setup: DeepSeek V4 Pro for routine text and coding, MiniMax M3 for visual or long-horizon tasks, a fallback model for outages, and a monthly review of cost per completed agent task.
Keep the Test Setup Simple
The best model comparison is clean and repeatable. If every test requires fixing hosting, reconnecting keys, updating packages, or chasing environment errors, the signal gets muddy. Keep the runtime stable, keep the task set consistent, and change one variable at a time.
Conclusion
MiniMax M3 vs. DeepSeek V4 Pro is a long context AI model comparison, but it is not a simple winner-takes-all decision. MiniMax M3 is the better model to test for multimodal, long-context, agentic workflows. DeepSeek V4 Pro is the better model to test first when cost-sensitive reasoning and coding throughput matter most.
Compare both on the same real tasks. Measure completed work, not first impressions. Track retries, tool accuracy, total cost, and human intervention. For an always-on AI agent, the runtime around the model matters as much as the model itself.
Пропустите настройку. Запустите OpenClaw прямо сейчас.
AgentCellar предоставляет полностью управляемый экземпляр OpenClaw (Clawdbot) — всегда онлайн, без DevOps. Планы от $19/мес.