
MiniMax M3 vs. Kimi K2.6: Which Model Is Better for AI Agents?
Alex Morgan 撰寫
AgentCellar 編輯團隊
AgentCellar
Get OpenClaw running now
了解託管、自動化、付款、客服支援與 OpenClaw 維運如何整合成完整的託管產品體驗。
AI Takeaway
- Which model is better for coding agents? MiniMax M3 is the stronger first test for visual, long-context, and desktop-like workflows. Kimi K2.6 is the stronger first test for long-horizon coding, tool use, self-correction, and parallel research.
- Does 1M context beat 256K context? Not automatically. MiniMax M3 helps with large repos, logs, screenshots, or documents. Kimi K2.6 can still win if it plans better and uses tools more reliably.
- Which model is cheaper? MiniMax M3 has the clearer token-quota story. Kimi K2.6 may still be cheaper when it needs fewer retries.
- What should you measure? Completed tasks, retry count, tool accuracy, latency, output tokens, and cost per finished agent run.
MiniMax M3 vs Kimi K2.6 at a Glance
MiniMax M3 and Kimi K2.6 are both built for more than chat. They are meant to handle coding, tools, longer context, and agent-style work.
The quick version: MiniMax M3 looks stronger when the agent needs to see more and hold more. Kimi K2.6 looks stronger when the agent needs to plan, coordinate, correct itself, and keep a long coding or research workflow moving.
| Area | MiniMax M3 | Kimi K2.6 |
|---|---|---|
| Best fit | Multimodal, long-context, visual, and desktop-like agent work | Long-horizon coding, tool use, planning, and swarm-style tasks |
| Context | Up to 1M context | 256K context |
| Standout capability | 1M context + native multimodal + coding/agent focus | Agent Swarm, self-correction, tool use, long coding sessions |
| First test | Large repo, screenshot failure, browser task, visual QA | Multi-step coding task, research swarm, tool-heavy execution |
| Main risk | New-model stability and long-context cost | Smaller context and swarm overhead |
For broader release details, API access, and long-context notes, use this MiniMax M3 guide. This article focuses on what happens when the model has to do real agent work.
The Real Question Is Not Which Model Chats Better
Chat Benchmarks Miss Agent Failures
A normal chat test can make both models look impressive. Ask for a summary, a function, or an explanation, and both may answer cleanly. Agent work is messier: the model has to inspect files, choose tools, call APIs, read logs, recover from failed commands, and know when the task is done.
Finished Work Beats First Impressions
For agent work, the useful question is not "which model sounds smarter?" It is "which model finishes the job with less help?"
Use a simple scoring frame:
- Did the task finish?
- Did the model use the right files and tools?
- Did it recover after a failed command?
- Did it avoid unnecessary output?
- Did it need a human rescue?
This matters especially for software work. A model that writes plausible code but misses the failing test has not saved much time. If coding is the main use case, test both models inside a real coding agent workflow.
Where MiniMax M3 Looks Stronger
1M Context for Large Repos and Long Sessions
 MiniMax M3's obvious advantage is its 1M context window. That matters when the task needs a lot of material nearby: a large repository, long browser research, multi-document analysis, product specs, error logs, or a long-running agent session.
MiniMax M3's obvious advantage is its 1M context window. That matters when the task needs a lot of material nearby: a large repository, long browser research, multi-document analysis, product specs, error logs, or a long-running agent session.
But 1M context is not magic. If the model cannot find the right detail inside the larger context, bigger input just becomes slower and noisier. Long context works best when files, logs, screenshots, and tool output are passed in a structured way.
Multimodal and Visual Agent Work
MiniMax M3 also has a strong case for visual work. If the agent needs to inspect screenshots, UI state, charts, PDFs, browser pages, or desktop-like tasks, MiniMax M3 is the more natural first test.
Think about a failed checkout layout or a screenshot showing a visual regression. A text-only model needs someone to describe the problem. A multimodal model can inspect the state directly.
Coding With Tools, Not Just Code Generation
The right coding test is not "which model writes a prettier function?" It is whether the model can read a repo, edit the right files, run validation, understand failures, and try again.
MiniMax M3 is worth testing when coding work combines repo context, logs, browser output, screenshots, and long sessions.
{{myclaw_blog_cta}}
Where Kimi K2.6 Looks Stronger
Long-Horizon Coding and Self-Correction
 Kimi K2.6 is compelling when the bottleneck is not raw context size, but staying organized across many steps. Long-horizon coding is often about persistence: make a plan, inspect the project, change files, run checks, read failures, adjust, and continue.
Kimi K2.6 is compelling when the bottleneck is not raw context size, but staying organized across many steps. Long-horizon coding is often about persistence: make a plan, inspect the project, change files, run checks, read failures, adjust, and continue.
If Kimi's hosted agent experience is part of the decision, this Kimi Claw review is a useful companion because it covers convenience, cost, safety, and where managed agent setups still have friction.
Agent Swarm for Parallel Search and Output
Kimi K2.6's Agent Swarm angle is different from MiniMax M3's 1M-context pitch. Instead of trying to keep everything in one long window, swarm-style execution splits large work into parallel sub-tasks.
That can help with broad discovery: collecting sources, comparing competitors, summarizing documents, drafting sections of a report, or exploring many branches of a research task at once. The caveat is that more agents can also mean more cost, noise, and coordination overhead.
Tool Use and Structured Workflows
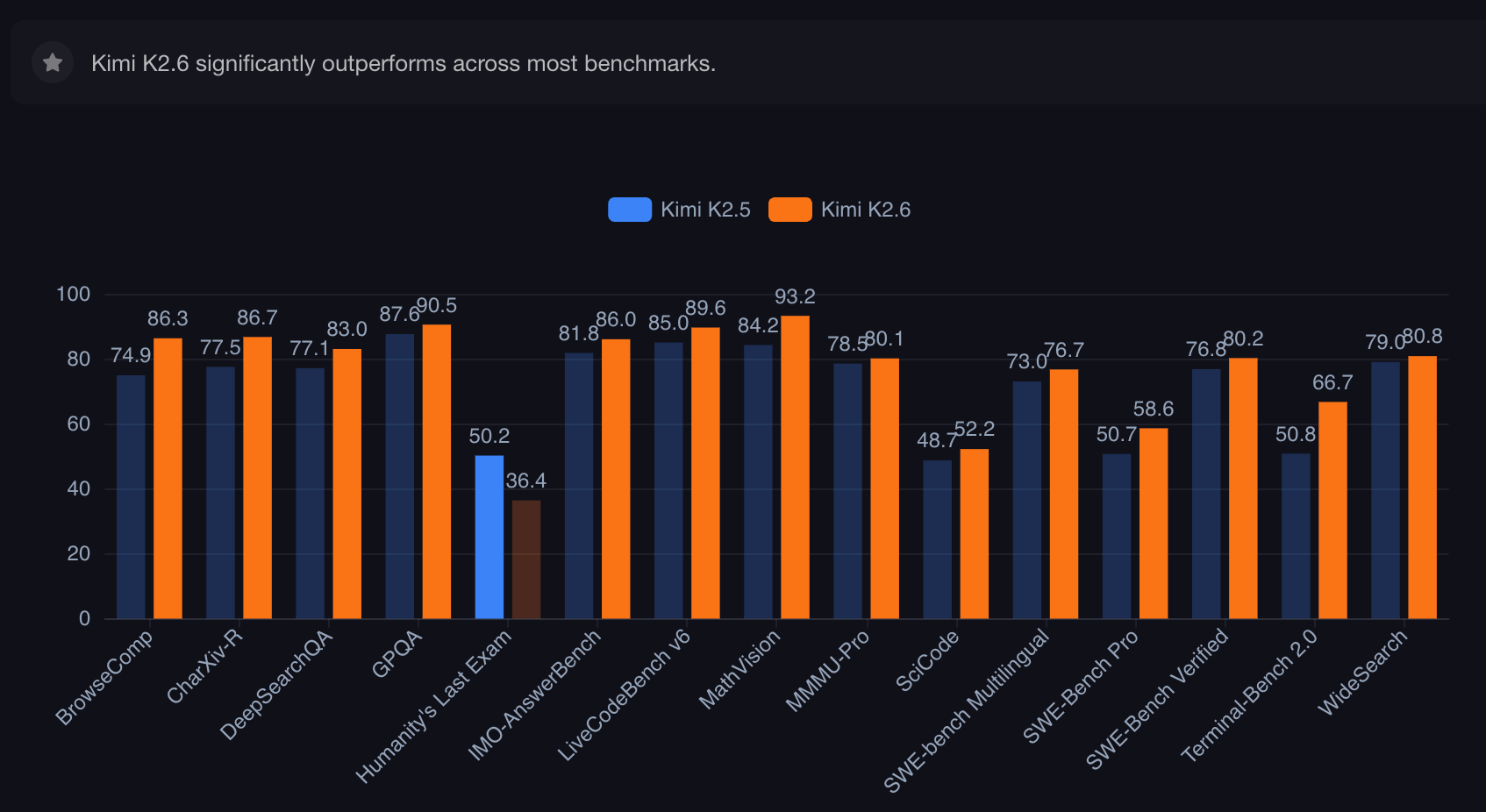 Kimi K2.6 should be tested heavily on tool calls, structured output, search, JSON-style workflows, and correction after mistakes. This is where it can beat a larger-context model.
Kimi K2.6 should be tested heavily on tool calls, structured output, search, JSON-style workflows, and correction after mistakes. This is where it can beat a larger-context model.
If it calls the right tool, keeps a clean task state, and avoids looping, it can finish faster even with less context.
1M Context vs 256K Context
MiniMax M3's 1M context matters when the task genuinely needs huge input: whole-repo exploration, many logs plus code, full transcripts, large PDF bundles, or long workflow history.
Kimi K2.6 can still win if it chooses better context, summarizes progress well, calls tools accurately, and avoids wasteful loops. Many real tasks do not need 1M tokens.
The best test is same runtime, same prompt, same files, same permissions, same budget, and same success criteria. If the runtime changes, the comparison gets muddy. You may end up testing the wrapper, not the model.
{{myclaw_blog_cta}}
Cost Is More Than Token Price
Compare Cost per Finished Agent Run
Token price is only the starting point. For agent work, total cost includes context, tool output, retries, failed runs, and final response length.
| Metric | Why It Matters |
|---|---|
| Input tokens | Long context can get expensive |
| Output tokens | Verbose models can cost more than expected |
| Retries | Failed runs multiply cost |
| Tool calls | Tool output adds context and latency |
| Human fixes | Cheap tokens are not cheap if the user rescues the task |
MiniMax M3 may be cheaper when one long-context run replaces repeated retrieval. Kimi K2.6 may be cheaper when it finishes in fewer attempts or splits work into useful sub-agent tasks.
Setup Cost Counts Too
 There is another cost that does not show up in an API table: setup time. If testing models means maintaining a VM, wiring tools, updating the runtime, and reconnecting keys, the model comparison becomes its own project.
There is another cost that does not show up in an API table: setup time. If testing models means maintaining a VM, wiring tools, updating the runtime, and reconnecting keys, the model comparison becomes its own project.
This is where MyClaw can make the test cleaner. MyClaw gives you a private hosted OpenClaw environment, so you can compare models inside an always-on agent runtime instead of spending the first day on infrastructure. It is not the model itself; it is the stable place where the model can actually do work.
For workflows that depend on retained context, a skill like self-improving agent also changes the test. A model's first run matters, but so does how the agent improves after repeated sessions.
Which Model Should You Use?
Choose MiniMax M3 If the Agent Needs to See More
Use MiniMax M3 for visual workflows, screenshot debugging, UI QA, browser state, large repositories, long document sets, and multimodal tasks.
Choose Kimi K2.6 If the Agent Needs to Coordinate Longer
Use Kimi K2.6 for long-horizon coding, multi-step tool use, swarm research, structured reports, and planning-heavy work.
Use Both for a Serious Agent Stack
The practical answer is often routing. Use one model for routine text or coding work, one for visual or long-context work, and a fallback when a provider is slow, costly, or unavailable.
For OpenClaw, this matters even more. The best setup is not always one model. It is a stable runtime that can choose the right model for the job. This best model for OpenClaw guide covers that model-stack view in more detail.
How to Test MiniMax M3 vs Kimi K2.6
Build a small task set from work you actually need done. Do not use only neat demo prompts.
Good tests:
- fix one failing test in a repo
- inspect a screenshot and repair a UI bug
- summarize a long document set
- research 20 sources and produce a table
- write a small feature and run validation
- analyze logs and identify root cause
- complete one browser automation task
Score every run the same way: completion, retries, time, total cost, tool mistakes, final output quality, and human intervention.
Keep the runtime fixed. Swap the model, not the whole environment. That is the cleanest way to see whether MiniMax M3's context advantage or Kimi K2.6's planning advantage matters more.
Conclusion
MiniMax M3 vs. Kimi K2.6 is not a simple benchmark fight. MiniMax M3 has the stronger 1M-context and multimodal story. Kimi K2.6 has the stronger long-horizon coding, tool use, and Agent Swarm story.
For real AI agents, the winner is the model that finishes the task with fewer retries, lower total cost, and less human rescue. Test both models on the same workflows, inside one stable agent runtime, and measure completed work instead of first impressions.
跳過設定。立即啟動 OpenClaw。
AgentCellar 為您提供全託管的 OpenClaw (Clawdbot) 智能體 — 始終在線、零 DevOps。方案 $19/月起。